 CN
CN
 JP
JP
 FR
FR
 ES
ES
 DE
DE
 NL
NL
 IT
IT
 PT
PT
 HI
HI
 UR
UR
 AR
AR
 BN
BN
 RU
RU
Specification driven development (SDD) encourages a "complete" spec written up-front in the hope that the detail can be used to more accurately drive AI agentic code generation.
This article suggests that producing a complete specification flies in the face of reality and argues that spec-driven development can be used incrementally.
What we have always known about waterfall
Waterfall does not work. If you agree with this, skip this section.
In Winston Royce's widely quoted paper from 1970, "MANAGING THE DEVELOPMENT OF LARGE SOFTWARE SYSTEMS", the author states that a software development process based on "requirements → design → coding → testing → operations" does not work. He explicitly says: "I believe in this concept, but the implementation described above is risky and invites failure."
The concept is sound. In software engineering, requirements must be captured before designing a solution that a software engineer will then code, test and release into production (operations). But a strict forward-only implementation of this does not work. Completing all requirements before moving on to design and completing that 100% before coding does not acknowledge the learning that will take place during the separate phases. When coding it is common for questions to arise that affect requirements that, in turn, impact the design.
Based on Royce's nine years of experience back in 1970 he knew that waterfall was risky and invites failure.
In the fifty years since, history has conspired to lay the Waterfall Method at Royce's door when, in fact, he was arguing for the opposite.
Royce was not advocating for waterfall
He described why Waterfall was risky and invited failure with an example. He said that when testing happens too late, unknown constraints only appear at the end, and the result is a need for costly rework.
As a strawman, he presented the classic waterfall diagram (figure 2 of his paper, not included here) with work proceeding forwards-only, from "analysis → design → coding → testing". He was not advocating waterfall as a realistic approach.
He was presenting what really happened on software delivery projects and showed that a forward-only waterfall did not acknowledge the reality of developing software where later events raise questions about earlier decisions.
In figure 3 (not included here) he showed that activities in process neighbours, such as program design and coding, affect and influence one another.
He then presented wider ranging effects in figure 4:
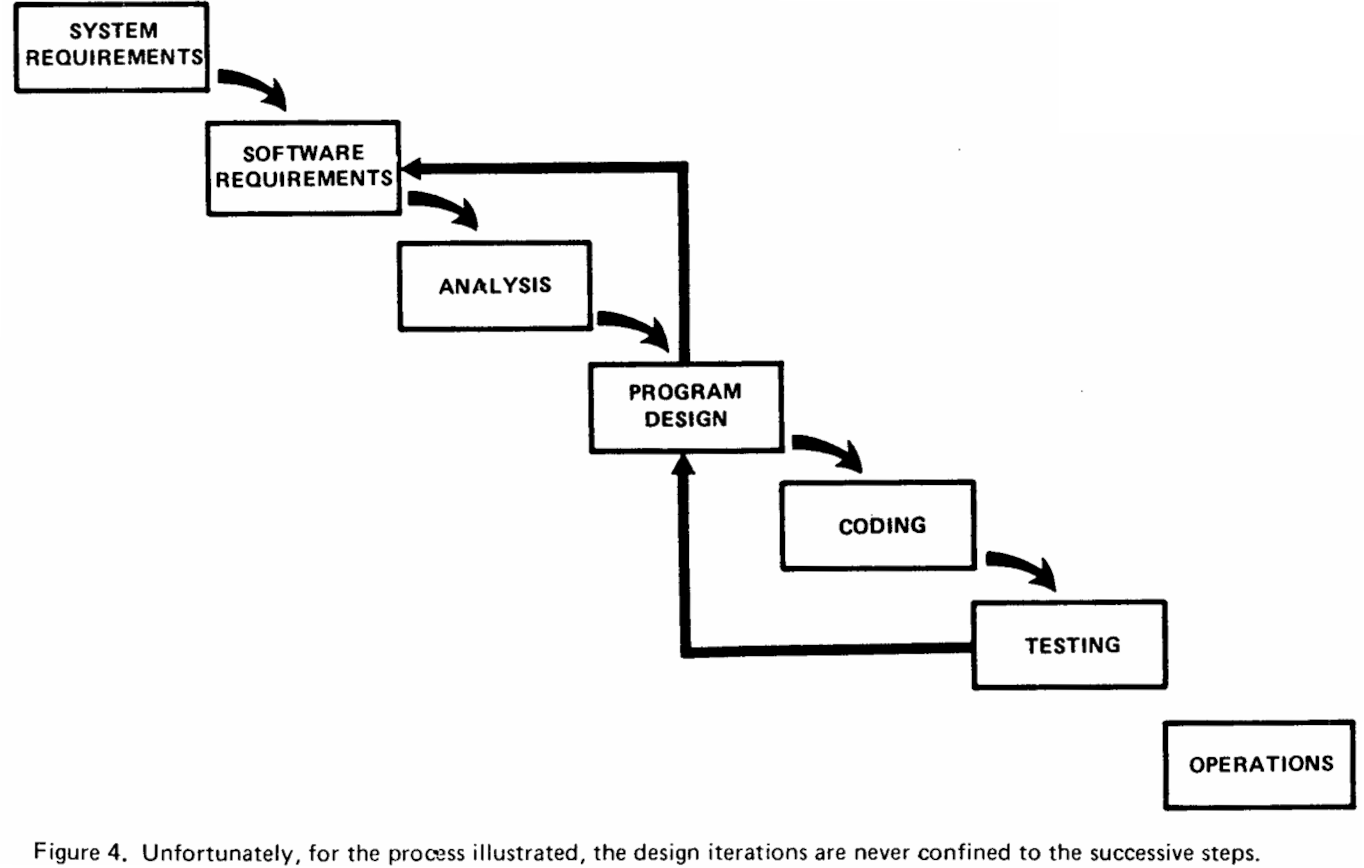
to illustrate what goes wrong with waterfall and why a siloed and stepwise sequence of "analysis → design → coding → testing" does not work.
Royce said:
"The testing phase which occurs at the end of the development cycle is the first event for which timing, storage, input/output transfers, etc., are experienced as distinguished from analyzed. These phenomena are not precisely analyzable."
This is a statement that you do not know what you have until you test it. This is because such phenomena are not analyzable and they only surface under test. There are certain aspects of your system that you cannot know at the analysis stage, and you will only discover what they are, and their wider impact, during testing.
For example, specifications describe intended user inputs but users provide edge-case inputs.
Unexpected Unicode characters can break a parser or a device sends malformed packets that a specification never anticipated or a user performs an action sequence no analyst imagined.
A specification defines a number of assumed input types. But only at the coding stage does it become clear what set of input instances can be entered, and the set of instances will highlight a number of missing input types. In short, the specification identifies the happy path, and only at coding do we see all paths.
He then says:
"If these phenomena fail to satisfy the various external constraints, then invariably a major redesign is required… The required design changes are likely to be so disruptive that the software requirements upon which the design is based and which provides the rationale for everything are violated. Either the requirements must be modified, or a substantial change in the design is required."
Royce was noting that the testing that you can see in figure 4 was too late and that testing late in delivery may require a substantial (and costly) change.
The 5 steps that introduce iterative, incremental engineering
Royce then presents 5 steps that break the idealised approach.
- Step 1: program design comes first
- Step 2: document the design
- Step 3: do it twice
- Step 4: plan, control and monitor testing
- Step 5: involve the customer
Waterfall assumes "requirements → analysis → design → code → test" so placing a program design phase at the start breaks waterfall.
Royce is clear that documentation must be kept up to date, that it is evolving and not a one-off per phase. He is clear that it is not fixed once produced, never to be touched again.
In step 3 the author states "Arrange matters so that the version finally delivered… is actually the second version insofar as critical design/operations areas are concerned." This is iterative prototyping, not waterfall.
In talking about testing for step 4 he says testing must be planned and staged with multiple test steps. He is clear that testing must be prepared for from the beginning.
Royce warns that "The testing phase… is the first event for which timing, storage, input/output transfers… are experienced… If these phenomena fail… a major redesign is required."
This is an anti-waterfall argument. Royce was arguing that testing cannot be left to the end because the end is too late to fix whatever you discover. Testing must be throughout the process and this implies testing must be incremental. What you learn from testing is fed back into earlier stages and you iterate. This is software engineering reality and Royce knew this in 1970.
For step 5, "Involve the customer", Royce stated: "It is important to involve the customer in a formal way so that he has committed himself at earlier points before final delivery." In his summary, he lists "Involve the customer" as one of five core guidelines, making customer involvement a first‑class concern rather than a one‑off at the end.
This is the opposite of waterfall because waterfall assumes customer involvement only at the beginning and end.
What Royce was describing
In describing steps 1 to 5, Royce is describing an early form of iterative, risk-driven development.
He is saying that if you try to run waterfall, you will fail. And that if you add everything you need to make that failed process work (steps 1 to 5), you no longer have waterfall: you have iterative delivery.
He was presenting a strawman
His presentation is a strawman. He describes a theoretic ideal in figure 2, the forward only process. This was picked up as the Waterfall Method. But Royce was not advocating for it. He was presenting it as an idealised theory, and that to do real software delivery, another approach was required that he outlined in steps 1 to 5.
Royce was advocating an iterative approach
To show what this other approach was, he elaborated figure 2 into figure 3, with backward steps between neighbours in the classical Waterfall.
The author then stated:
"there is an iteration with the preceding and succeeding steps [from figure 2] but rarely with the more remote steps in the sequence. The virtue of all of this is that as the design proceeds the change process is scoped down to manageable limits."
He is stating that there can be iteration between any pair of stages: "rarely with the more remote steps" does not rule out that iteration cannot occur at any stage, only that such iteration is rarer than for stages that are neighbours.
He is also pointing out that things will change: "as the design proceeds, the change process is scoped down to manageable limits." Royce knew in 1970 that change was fundamental to delivery, and that effort had to be expended to explicitly handle it.
He goes on to say:
"At any point in the design process after the requirements analysis is completed there exists a firm and closeup, moving baseline to which to return in the event of unforeseen design difficulties."
Royce is acknowledging that there may be unforeseen design difficulties and that those involved may have to return to earlier phases to mitigate this.
The caption for figure 3 shows his grasp of reality: "Hopefully, the iterative interaction between the various phases is confined to successive steps." This acknowledges the reality that this is not always the case.
Royce explicitly states this reality in the caption for figure 4: "Unfortunately, for the process illustrated, the design iterations are never confined to the successive steps". Royce knew that software engineering did not proceed neatly, forward-only step-by-step, and that progress in one activity may require another to be revisited.
What Royce presented
Winston Royce gives a summary of his approach in figure 10:
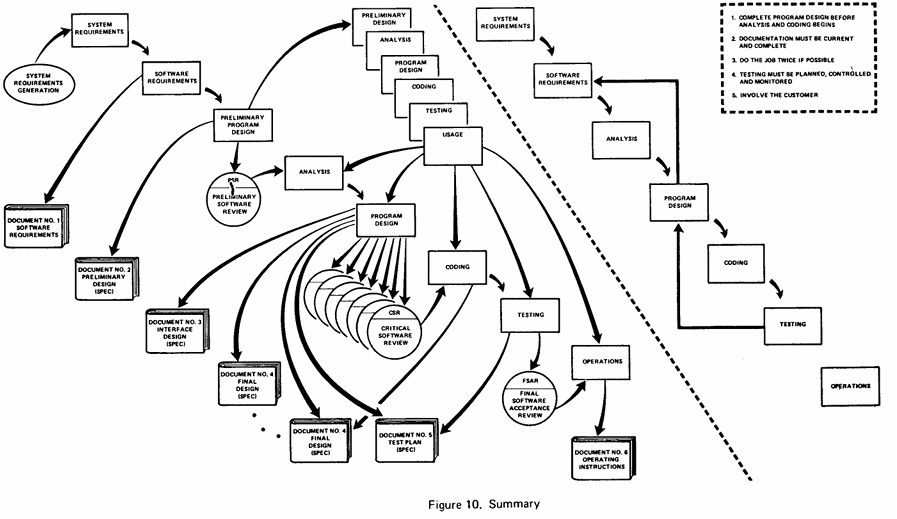
He says:
"Figure 10 summarizes the five steps that I feel necessary to transform a risky development process [figure 2, classical Waterfall] into one that will provide the desired product. I would emphasize that each item costs some additional sum of money. If the relatively simpler process without the five complexities described here would work successfully, then of course the additional money is not well spent. In my experience, however, the simpler method [Waterfall] has never worked on large software development efforts and the costs to recover far exceeded those required to finance the five-step process listed."
His last sentence says it all. Italics have been added.
Why does waterfall fail
Waterfall fails for two main reasons.
- it is not possible to know everything about a product before you start coding
- facts that come to light today necessitate revisiting earlier decisions
Attempting to know everything is a fool's paradise
If a system contains even a single component capable of unbounded variation, then a finite specification cannot capture all possible behaviours, and any claim to completeness contradicts itself.
Assume we have fully specified a system called S. Every possible behaviour is known and listed. This complete specification is called Spec(S). Because any written specification is finite1, Spec(S) contains only finitely many behaviours.
Within S, there is a component A that can produce specified behaviour at random. Randomness gives A unbounded variation. Component A can generate arbitrary sequences of behaviours. Such sequences are not described in Spec(S), because Spec(S) is finite and cannot list everything in a set with no end.
Therefore, the specification is not complete.
This is a self-contradiction. No finite specification can describe everything about a system that contains unbounded variation.
Even if the components of the system do not exhibit unbounded variation, the design of the environment that the implementation of S is deployed within introduces it.
Real multi-service, distributed systems contain effective unbounded variation through timing jitter, concurrency interleavings, randomness, and the combinatorial explosion of partial‑failure sequences.
In a distributed system nodes fail, messages can be delayed, reordered, duplicated or dropped, clocks drift, partitions break and heal, and nodes recover. Each of these can occur in any order, at any time, with any overlap. This is effectively unbounded variation.
A distributed system on its own can generate more behaviours than any finite specification can enumerate.
If there is no randomness
If component A has no unbounded variation, then Spec(S) can be complete.
This requires A to be fully deterministic, have no randomness and be subject to no timing jitter, be unaffected by concurrency, cannot learn or adapt, and has no interaction with other non-deterministic components.
If this is true, A's behaviour space is finite.
If every component in S is like this, then Spec(S) can enumerate all behaviours, and Spec(S) in this case is complete.
However, this is not a real-world system. It is the world of finite automata, simple synchronous circuits, textbook Turing machine examples, and closed, trivial, non-interactive systems. Such systems have value, but they are toy systems. They are not real systems.
In short, you cannot fully specify a real system because that system will contain unbounded variation and the runtime environment that hosts that system will definitely introduce such variation.
Royce's key observation
Royce's key insight was that Waterfall does not work because you cannot know whether some aspects of your work are right until you test them.
This may be the explicit test of code or it may be the implicit test of your idea by deploying to production.
Either way, attempting to do a complete job is risky because that completeness pushes your ability to test your ideas out too far.
What is preferable is to do a tiny slice, test that code and get it into the hands of your users, and if their signals are positive, do more.
If you design more up front, code all of it and deploy that you risk aspects of that fuller deployment not being used or liked. You could have avoided this with the tiny slice approach.
TinySlice
I define TinySlice to encourage you to think in the smallest of terms possible. In the TinySlice approach, much less is more.
Take a coherent tiny slice that solves a user problem and perform all the work from product and engineering to refine that into production. You will then get valuable feedback from your customers, and you can go from there.
TinySlice is compatible with Agile. You can do TinySlice within Agile. TinySlice sizes the work to be done, erring on the side of less not more. We only do more when we have had the feedback that says expending effort on more is warranted.
We may think we know what is required but this will only be known after we have tested our ideas. A specification is just documentation for our ideas.
We do this test by taking a TinySlice: refining, building and deploying it to get something into the hands of our users.
They use it and give us feedback. This feedback leads to two broad categories of what can be done next: new features, or changes to existing ones. And then we iterate.
What is SDD?
As of June 2026, the main vendor promoting Specification Driven Development (SDD) is Cognition Labs. This section focuses on Cognition's approach to SDD.
Cognition’s SDD is fundamentally a technique to generate code using their AI tool, Devin. SDD is not a full software‑engineering methodology, not a lifecycle model, and not a requirements discipline. It is a workflow designed to support how Devin operates.
Cognition's SDD is:
- specification as input
- agent-driven code generation
- code regeneration from an update specification
It defines none of the disciplines that keep code generation safe and accurate. Such disciplines are: requirements, design, testing, governance, iteration, risk, and architecture.
Cognition and SDD
SDD is not an engineering method
Cognition’s SDD is a code‑generation loop, not an engineering method. It treats the specification as a prompt for Devin, generates the system from it, and regenerates the system when the specification changes. It is a technique for driving an AI agent, not a process for discovering requirements, managing risk, or iterating design.
The output of Cognition's SDD is code, not understanding. At the code generation step, there is no support for:
- architectural reasoning
- trade‑off analysis
- risk mitigation
- incremental discovery
Cognition hints that SDD requires a full specification
Cognition describes the specification as the main input from which Devin generates a plan, produces tasks, and provides the code implementation.
By doing this, Cognition implies that the specification must be complete enough to accurately drive the generation steps without ambiguity.
This nudges teams towards writing as full a specification as possible "just in case".
Distinguishing SDD from the competition
To distinguish Devin from Cognition's competitors — Copilot, Cursor, Replit, Claude Code, Jetbrains AI — Cognition positions other approaches as generating code from prompts whereas Devin generates systems from specifications.
For this approach to be meaningful, the specification must appear formal, complete, and central.
Using Devin
Cognition state that the Devin pipeline is:
- write specification
- Devin generates plan
- Devin produces tasks
- Devin outputs code
There is no Devin-based loop, no iteraction, no feedback cycle. The approach is spec → Devin → system. If things change, you update the spec and re-run: spec → Devin → system.
This implies that SDD and Devin are waterfall in style.
TinySlice and SDD
TinySlice assumes incompleteness is normal. You cannot know enough upfront, so you deliberately work in the smallest possible increment. Working with small increments gives you evidence that what you are doing is the right thing.
As Cognition describe and demo it, SDD is an authorative input, and that the pipeline is linear and waterfall-shaped.
You can use TinySlice with SDD if you treat SDD as a code generator inside your own iterative loop.
Conclusion
Complete specifications are an illusion. Real systems contain unbounded variation.
Real engineering requires learning from what the system actually does, not from a specifiction that tries to capture what we think it should do.
TinySlice accepts this reality. TinySlice gives us a disciplined way to move forward in the smallest increments possible, gathering evidence at every step.
Pairing agentic code generation with an incremental, evidence‑driven engineering practice is a safe way forward given the volume of code that AI can generate.
Creating a complete specification delays learning and insight, increases risk and pushes project discovery too late. Winston Royce understood this in 1970.
TinySlice acknowledges his insight. By working in the smallest viable increments, we surface unknowns early, reduce rework and can steer more accurately to quickly react to change.
SDD can play a role, but only when we stop treating the specification as authoritative and start treating it as provisional, as a living document that must change.
Read next: Why Junior Engineers Matter More as AI Expands
AI means code generation is now trivial but speed cannot decide what should exist, why it matters, or whether it is safe. Junior engineers cannot bypass the discipline to gain this judgement.
Related Articles
If this was useful, you can get more pieces like it in the Phroneses newsletter.
I work with leaders and teams on clarity, capability, and momentum. Work with me →
Table of Contents
- What we have always known about waterfall
- Royce was not advocating for waterfall
- The 5 steps that introduce iterative, incremental engineering
- What Royce was describing
- What Royce presented
- Why does waterfall fail
- Royce's key observation
- TinySlice
- What is SDD?
- Cognition and SDD
- TinySlice and SDD
- Conclusion
- Related Articles
- Table of Contents
- Further Reading
Further Reading
Winston Royce, 1970, "MANAGING THE DEVELOPMENT OF LARGE SOFTWARE SYSTEMS"
- https://www.praxisframework.org/files/royce1970.pdf
-
A written specific must be finite. Is not possible to complete the writing of an infinite specification. ↩